TL;DR
下記リポジトリで色々試しています。
Ollamaとは?
Ollamaは、ローカル環境で大規模言語モデル(LLM)を簡単に実行できるオープンソースのツールです。
下記はPerplexityが出力した内容になります。(2025年01月25日現在)
主な特徴は以下の通りです:
- ローカルでLLMを動作させるため、外部サーバーに依存せずにAI機能を利用できます3.
- Llama 2、Mistral、Vicuna、Phiなど、様々なオープンソースモデルをサポートしています45.
- コマンドラインインターフェース(CLI)とAPIを通じて簡単に操作できます4.
- MacやLinuxで動作し、Windowsにも対応予定です3.
- モデルのカスタマイズやファインチューニングが可能です4.
- プライバシーを保護しつつ、クラウドAPIのコストを回避できます4.
- PythonやTypeScriptのライブラリが提供されており、開発者にとって使いやすい環境が整っています5.
Ollamaは、ローカルLLM管理のためのDockerのようなエコシステムを提供し、AIアプリケーション開発者がモデルごとの実装の違いを気にせずに開発できるようサポートします2. これにより、テキスト生成、質問応答、要約など、高度なAI機能をローカル環境で手軽に利用できるようになります3.
Ollamaのダウンロード
下記サイトからOSに合わせてダウンロードします。
ダウンロードが完了すると、コマンドプロンプトでollamaコマンドが利用できるようになります。
$ ollama -v
ollama version is 0.5.7Ollamaの使い方
ollamaが起動している時は、http://127.0.0.1:11434/ でOllamaサーバーが立ち上がります。
$ curl http://127.0.0.1:11434/
Ollama is running※ もしollamaサーバーが立ち上がっていない場合は、下記コマンドを試してください。
ollama serveLLMをダウンロードする
ダウンロード可能なLLMは下記サイトから探すことができます。
ここでは、Meta社が提供するLlamaをダウンロードしてみます。
ollama pull llama3.2下記コマンドでダウンロードしたLLMを確認できます。
ollama list下記コマンドでダウンロードしたLLMを実行することができます。
ollama run llama3.2
ちなみに、Hugging Face上でGGUF形式で提供されているモデルもダウンロード可能です。
GGUFは、LLM(大規模言語モデル)をコミュニティハードウェア上でインファレンスするための新しいファイル形式です13。GGUFは"Georgie Character Unified Format"(ジョージーキャラクター統一フォーマット)の略称で、以前のGGMLやGPTQ形式に代わる拡張性の高いフォーマットとして開発されました13。GGUFの主な特徴と利点は以下の通りです:
- 高い拡張性: GGUFは統一ファイル形式であり、Llama以外の言語モデル(Falcon、Bloom、RWKVなど)もサポートできるようになりました13。
- プロンプトのカスタマイズ: GGUFにはプロンプトのカスタマイズオプションがあり、不要なパラメーターを気にする必要がありません1。
- 効率的なパフォーマンス: メモリ消費を抑えながら効率的なパフォーマンスを実現します2。
- 複数の構成: Q2からQ8まで複数の構成で提供され、幅広いGPU機能に対応しています2。
- ファイル拡張子の変更: 従来の".bin"から".gguf"に変更されました3。
GGUFは、特にリソースが限られた環境や低スペックのハードウェアでAIモデルを実行する際に有用です。このフォーマットにより、ユーザーはシステムのパフォーマンスに最適なバージョンを選択できるようになりました2。
下記は、ollamaで利用可能な日本語に強いモデルらしい。(17GBあるので注意)
ollama run hf.co/mradermacher/creative-writer-plus-32b-preview-01-2025-GGUF:IQ4_XSカスタムLLMを作成する
ベースとなるLLMとシステムプロンプトやtemperatureなどのパラメータを定義したModelfileを用いて、カスタムLLMを作成することができます。
下記は、Llama3.2をベースに日本語用のAIアシスタントとしてカスタマイズされたLLMのModelfileです。
FROM llama3.2
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# set the system message
SYSTEM """You are a highly proficient Japanese-speaking AI assistant. You must conduct all conversations with users in Japanese. **Crucially, you must think and formulate your responses in Japanese.**"""※ ollamaのshowコマンドを使うと、Modelfileの雛形を出力することができます。
ollama show llama3.2 --modelfile > Modelfile下記コマンドでModelfileからカスタムLLMを作成できます。
ollama create llama-jp -f ./Modelfile
ollama run llama-jp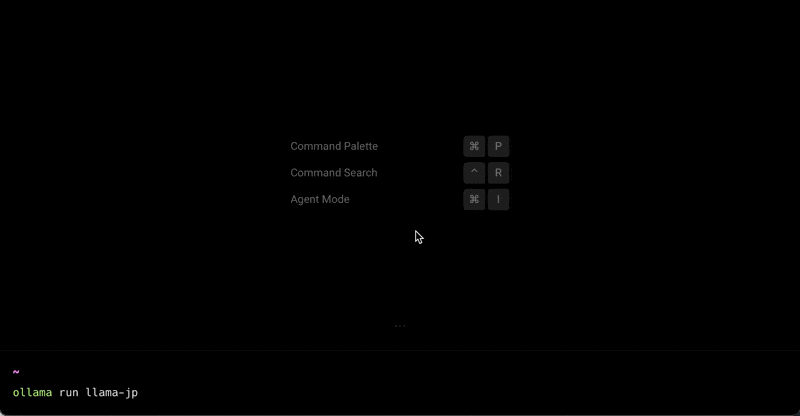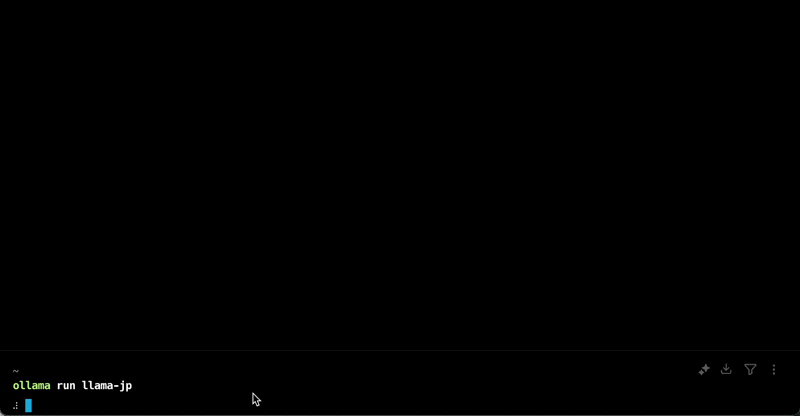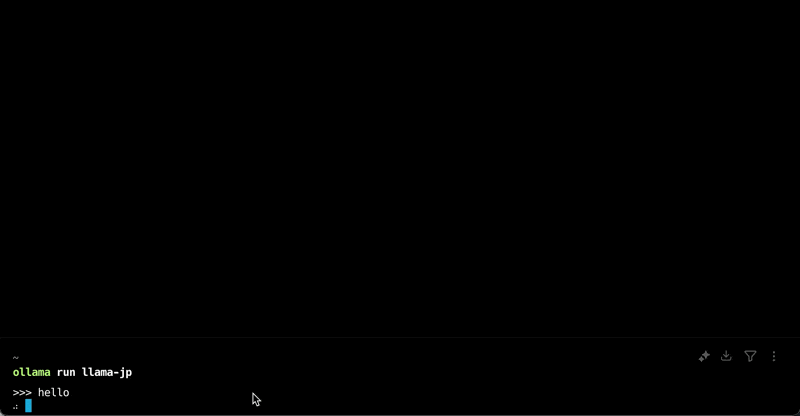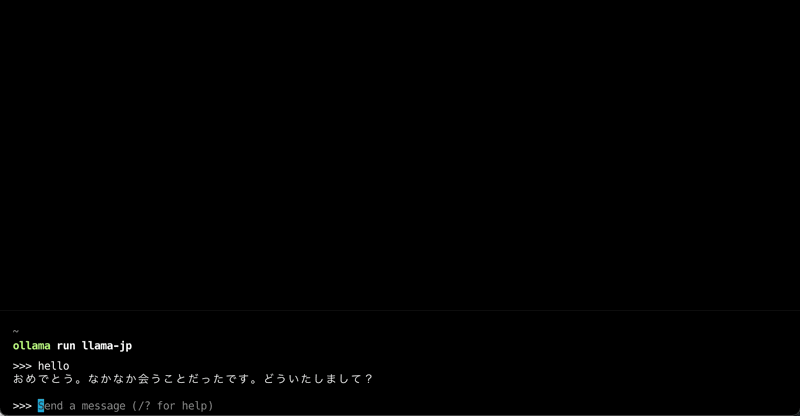
Open WebUI
Open WebUIとは、AIプラットフォームをGUIで実行するためのアプリケーションをセルフホストするためのオープンソースツールです。
Docker Imageが提供されているので、dockerで実行してみます。
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://host.docker.internal:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainhttp://localhost:3000にアクセスすると、ollamaでダウンロードしたLLMをGUI上で実行できるようになります。
OllamaをDockerで起動する
OllamaもDocker Imageが提供されているので、Dockerで起動することが可能です。
下記は、OllamaとOpen WebUIを立ち上げるDocker Composeのサンプルです。
services:
open-webui:
container_name: open-webui
image: ghcr.io/open-webui/open-webui:git-24ab79f-ollama
restart: always
ports:
- 3000:8080
volumes:
- open_webui_data:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://host.docker.internal:11435
ollama:
container_name: ollama
image: ollama/ollama:0.5.7
ports:
- 11435:11434
volumes:
- ollama_data:/root/.ollama
volumes:
open_webui_data:
driver: local
ollama_data:
driver: local以下コマンドでサービス群を立ち上げることができます。
docker compose up -d以下コマンドでLLMをダウンロードできます。
docker compose exec ollama ollama pull llama3.2http://localhost:3000にアクセスすると、ollamaでダウンロードしたLLMをGUI上で実行できるようになります。
Ollama JavaScript Library
OllamaサーバーのAPIをJavaScriptで実行するためのライブラリです。
ここでは、推論モデルのDeepSeek-R1(1.5b版)と日英翻訳モデルのgemma-2-jpn-translateを組み合わせて、非常に軽量で日本語でも高精度なLLMを作成します。
- DeepSeek-R1(1.5b): 1.1 GB
- gemma-2-jpn-translate:3.3 GB
下記はTypeScriptで記述した例になります。
参考:https://zenn.dev/masato13/articles/5af9d8d0f60b2b
/**
* deepseek r1 の軽量モデルは日本語に弱い(中国語と英語を学習に使用する)モデルであるため、
* 翻訳モデルと組み合わせて日本語でも十分な精度を出せるようにするサンプル
*/
import { Ollama } from "ollama";
const ollama = new Ollama({ host: "http://127.0.0.1:11434" });
/** 推論モデル https://ollama.com/library/deepseek-r1:1.5b */
const DEEPSEEK_R1_1_5B = "deepseek-r1:1.5b";
/** 翻訳モデル https://ollama.com/7shi/gemma-2-jpn-translate:2b-instruct-q8_0 */
const GEMMA_2_JPN_TRANSLATE_2B_INSTRUCT_Q8_0 =
"7shi/gemma-2-jpn-translate:2b-instruct-q8_0";
/**
* モデルのロード
*/
const loadModel = async () => {
console.log("Loading models...");
try {
// 推論モデル
await ollama.pull({
model: DEEPSEEK_R1_1_5B,
});
// 翻訳モデル
await ollama.pull({
model: GEMMA_2_JPN_TRANSLATE_2B_INSTRUCT_Q8_0,
});
} catch (error) {
console.error("Failed to load models.");
console.error(error);
process.exit(1);
}
console.log("Models loaded.");
};
/**
* 日本語から英語への翻訳
*/
const translateToEnglish = async (message: string) => {
const response = await ollama.chat({
model: GEMMA_2_JPN_TRANSLATE_2B_INSTRUCT_Q8_0,
messages: [
{ role: "system", content: "Translate Japanese to English:" },
{ role: "assistant", content: "OK" },
{ role: "user", content: message },
],
stream: true,
options: {
temperature: 0.0,
}
});
return response;
};
/**
* 英語から日本語への翻訳
*/
const translateToJapanese = async (message: string) => {
const response = await ollama.chat({
model: GEMMA_2_JPN_TRANSLATE_2B_INSTRUCT_Q8_0,
messages: [
{ role: "system", content: "Translate English to Japanese:" },
{ role: "assistant", content: "OK" },
{ role: "user", content: message },
],
stream: true,
options: {
temperature: 0.0,
}
});
return response;
};
/**
* 推論する
*/
const think = async (message: string) => {
const response = await ollama.chat({
model: DEEPSEEK_R1_1_5B,
messages: [{ role: "user", content: message }],
stream: true,
options: {
temperature: 0.7,
}
});
return response;
};
const main = async () => {
await loadModel();
const MESSAGE = "なぜ空は青いのですか?";
console.log("========================================");
console.log("1. translateToEnglish");
console.log("========================================");
const englishMessageStream = await translateToEnglish(MESSAGE);
let englishMessage = "";
for await (const part of englishMessageStream) {
englishMessage += part.message.content;
process.stdout.write(part.message.content);
}
console.log("\n");
console.log("========================================");
console.log("2. think");
console.log("========================================");
const thinkMessageStream = await think(englishMessage);
let thinkMessage = "";
for await (const part of thinkMessageStream) {
thinkMessage += part.message.content;
process.stdout.write(part.message.content);
}
thinkMessage = thinkMessage.replace(/<\/?think>/g, "").trim();
console.log("\n");
console.log("========================================");
console.log("3. translateToJapanese");
console.log("========================================");
const japaneseMessageStream = await translateToJapanese(thinkMessage);
let japaneseMessage = "";
for await (const part of japaneseMessageStream) {
japaneseMessage += part.message.content;
process.stdout.write(part.message.content);
}
};
main();コード上でもLLMをpullするコードが記載されていますが、事前にollamaコマンドでpullしておくことをおすすめします。
ollama pull deepseek-r1:1.5b
ollama pull 7shi/gemma-2-jpn-translate:2b-instruct-q8_0TypeScriptファイルを実行すると、LLMの出力を確認できます。
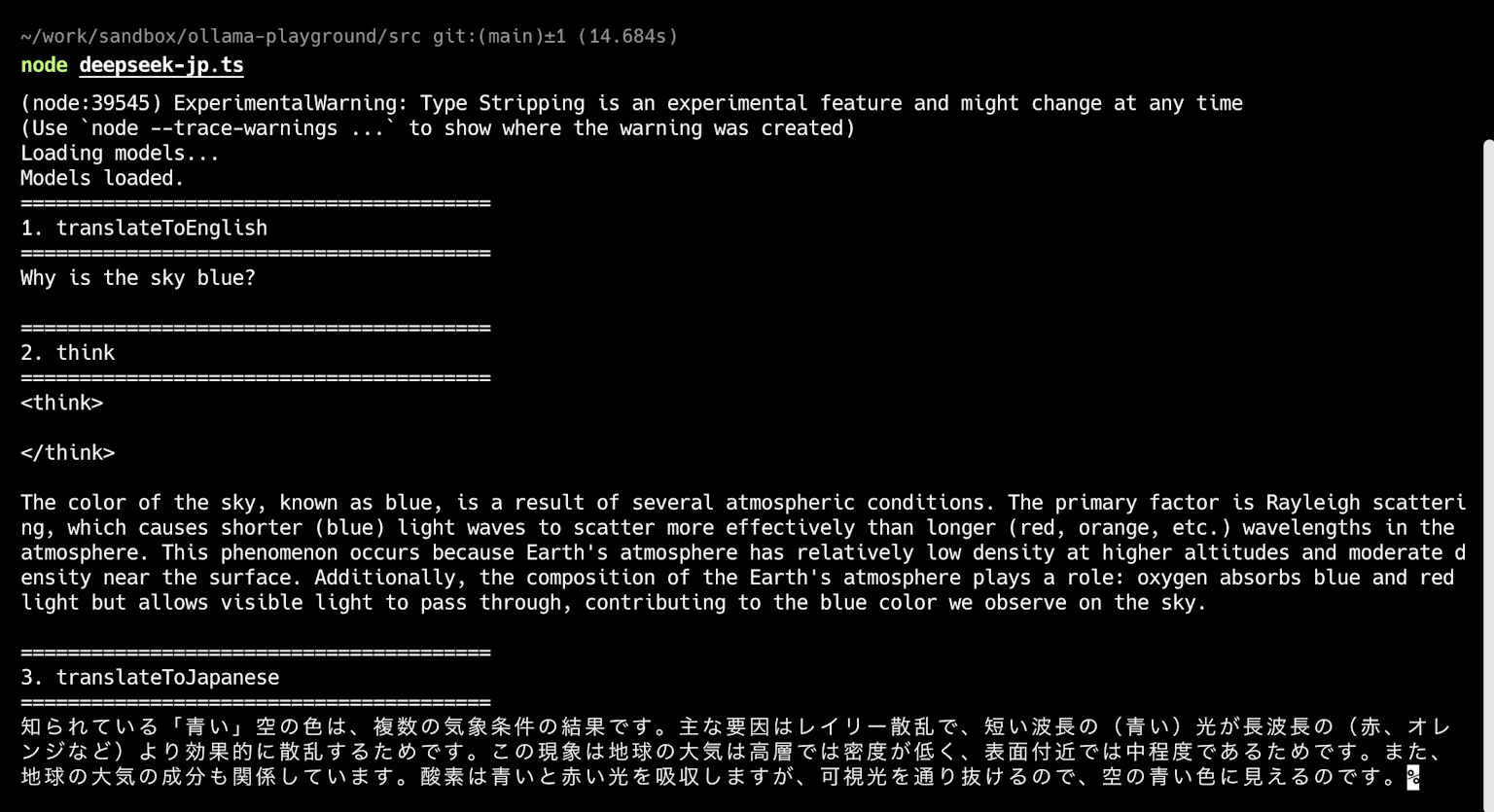
直接DeepSeek-R1(1.5b)を実行した場合の出力はこのようになります。

個人的に気になるLLMを紹介
deepseek-r1
2025年1月現在、今一番話題のLLM。ただの確率モデルではなく、言葉の意味をとらえて出力をする推論モデル。高精度なのに、非常に軽量なのも特徴。
Aratako/calm3-22b-RP-v2
cyberagent/calm3-22b-chatをベースにロールプレイ用にQLoRAでファインチューニングしたモデル。
ワークアラウンド
MacOSでOllama.appを起動した場合、Ollamaサーバーをkillできない問題があるので、下記コマンドでOllama.appを終了させる必要があります。
osascript -e 'tell app "Ollama" to quit'参考: https://github.com/ollama/ollama/issues/2372